Another day, another AI app idea. As I have been discussing earlier I do a daily walk in the woods. From time to time I walk around with my headphones on and start to talk about my day into the voice recorder on my iPhone. I enjoy structuring my thoughts this way, as I get to really think through ideas I had that day. However that is where most of the times it ends. Very sporadically I end up transcribing and summarizing my audio file with ChatGPT, but most of the time I don’t want OpenAI to know my raw thoughts. I later came back to this with local voice dictation for AI prompts. The recordings are messy and often contradictory. There is no follow up and the recording just becomes stale over time as I don’t do anything with it.
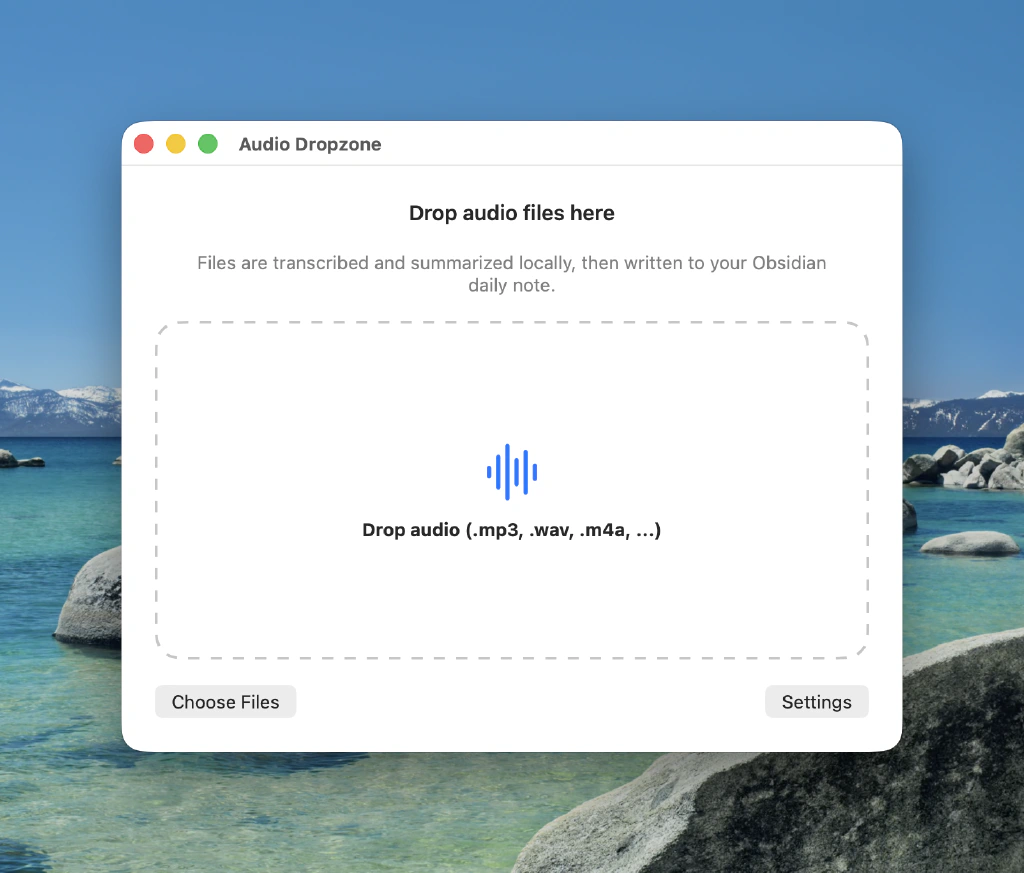
That is something I wanted to fix, but in a way that is very low friction. What if I could have a small MacOS app that runs in my menu bar that I could drop the audio file in. And then starts to automatically transcribe and summarize my ramblings on my local machine. That would be super helpful turning the chaos in my brain into something coherent, but what if that is automatically added to my Obsidian vault as a daily note for the day the audio file was recorded. Even better!
So I set out to start creating a prompt for OpenAI Codex. I find that I easily default to OpenAI tools as my plus account accommodates my needs perfectly fine and reduces my cognitive load. This lowers the barrier to actually start building and makes me go super fast. I wish to start experimenting with Claude Code as well, but so far I don’t have had a very good use case as Codex works really well IMO.
Attached Document
Execution Plan: Created by Codex Based on My Answers
Build Plan: Local macOS Menu Bar Transcription App (Dutch) -> Obsidian Daily Note
Summary
Create a native macOS menu bar utility in /Users/hugo/Development/local-transcription-bot that lets you drop audio files, transcribes locally with faster-whisper (Systran/faster-whisper-large-v3), cleans and summarizes with local Ollama (qwen3.5:35b-a3b default), and appends the result to your Obsidian daily note for the audio file creation date.
The note will contain summary only (not transcript), while full artifacts are retained locally indefinitely for reprocessing and tuning.
Implementation Scope (Decision-Complete)
App Shell (Swift + SwiftUI, Menu Bar)
MenuBarExtraapp with:- Drop zone window/panel for audio files.
- Queue/status list (queued/running/success/error).
- Settings window for models, vault, summary controls.
- Duplicate detection prompt on repeated file hash (
Replace/Append/Cancel) because you chose “ask each time”.
First-Launch Setup
- Vault picker (security-scoped bookmark) and persistence.
- Auto-bootstrap Python virtual environment in app support directory.
- Auto-install pinned dependencies for transcription.
- Validate local services:
ollamareachable athttp://127.0.0.1:11434ffmpegavailable.- Auto-download transcription weights on first run (
Systran/faster-whisper-large-v3).
Transcription Pipeline
- Input: dropped audio file.
- Compute SHA-256 hash for dedupe/idempotency.
- Normalize audio via
ffmpegto 16k mono WAV temp file. - Run Python worker (
faster-whisper) with: - Model:
Systran/faster-whisper-large-v3(default, configurable later) - Language: forced
nl(Dutch) - Return raw transcript text as JSON.
- No timestamps in final Obsidian note output.
Cleanup + Summary Pipeline (Ollama API)
- Two sequential calls to local Ollama:
- Cleanup prompt (Dutch): improve punctuation/grammar, remove fillers, preserve meaning.
- Summary prompt (Dutch): structured action summary.
- Long transcript strategy: chunk + merge
- Chunk cleaned transcript
- Summarize each chunk
- Final merge-summary pass.
- Summary controls in settings:
- Length (
kort,normaal,uitgebreid) - Tone (
zakelijk,neutraal,informeel) - Section toggles (key points, decisions, actions, open questions)
- Custom instruction text.
- Prompt builder composes stable base prompt + controls + custom instruction.
Obsidian Integration
- Read vault
.obsidianconfig first to resolve daily note folder/pattern. - Fallback to
YYYY-MM-DD.mdif settings unavailable. - Resolve target date from audio file creation date.
- Auto-create missing daily note file.
- Insert at end of file (your preference).
- Append summary block only, with metadata header:
- Source filename
- Created date/time
- Job hash/id
- Processing timestamp
- If duplicate detected, show choice dialog before write.
- Read vault
Local History & Storage
- Keep history indefinitely (your preference).
- Store per-job artifacts in Application Support:
- raw transcript
- cleaned transcript
- chunk summaries
- final summary
- logs + request metadata
- Enable re-run summary with updated tuning without retranscribing (if transcript exists).
Public APIs / Interfaces / Types
Python Worker CLI Contract
- Command:
python worker.py --input <path> --model <name> --language nl --output <json>- JSON output schema:
job_id,duration_sec,language,segments[],raw_text,warnings[],error.
Swift Internal Job Model
TranscriptionJob:id,sourceURL,fileHash,createdAt,status,error, artifact paths.SummaryProfile: length/tone/section toggles/customInstruction.AppSettings: vault bookmark, daily-note strategy, model names, duplicate policy default.
Ollama HTTP Integration
- Endpoint:
POST /api/generate - Request includes selected model + deterministic generation params.
- Response parsing with retry/backoff on transient failures.
- Endpoint:
Obsidian Note Block Format
- Stable marker for dedupe/replace support:
<!-- ltb:job:<hash> -->- Human-readable heading + summary body.
- No timestamps in transcript because note is summary-only.
Test Cases and Scenarios
Setup & Environment
- First launch with missing venv/deps -> successful auto-bootstrap.
- Ollama offline -> clear actionable error.
- Missing ffmpeg -> clear install guidance.
Transcription
- Valid Dutch audio -> raw transcript generated.
- Unsupported/corrupt audio -> graceful failure and no note write.
- Large file -> completes with chunked summary pipeline.
Summary Tuning
- Change length/tone/toggles -> output format changes as expected.
- Custom instruction influences summary while keeping required structure.
- Chunk+merge produces coherent final summary (no truncation).
Obsidian Write
- Existing daily note -> append at end.
- Missing daily note -> auto-create then append.
- Plugin-configured daily note path/pattern discovered correctly.
- Duplicate file drop -> prompt appears; replace/append/cancel each verified.
Data Integrity
- History artifacts saved for every successful job.
- Restart app -> history and settings persist.
- Re-summarize from stored cleaned transcript works without retranscription.
Performance/UX
- Progress states update correctly in menu UI.
- Concurrent drops queue deterministically.
- Cancel job stops downstream steps safely.
Assumptions and Defaults Chosen
- Earlier whisper.cpp intent is superseded by your explicit choice: faster-whisper backend with
Systran/faster-whisper-large-v3. - Default Ollama summary model:
qwen3.5:35b-a3b(configurable in settings). - Daily note filename default interpreted as
YYYY-MM-DD.md(example:2026-02-27.md), with Obsidian config parsing as primary source. - Note output is summary only; cleaned/raw transcripts are stored locally, not written into the note.
- Language is fixed to Dutch for transcription cleanup and summary output.
- History retention is indefinite unless a later cleanup feature is added.
Then the back and forth between Codex and me started again. This is becoming something I start to get used to, it comes with a version that is about 80% correct and then it needs some iterations on some missed dependencies and crashes. Things like that still happen, but after a few tries it gets it fixed and working correctly.
After about 90 minutes I had the final version running with the result I wanted. I dragged the audio file from Voice Memo app into the drop zone. It started downloading the local models needed, transcripts my audio file and summarized it. All removing repetition and giving me insights I was unaware of before reading the summary. Then as the finishing touch it was automatically being added as a daily note in my note taking app.
The main question I had was would my ramblings and the way I speak change now that I know that the result will become structured and coherent?
Before my thoughts during the walks were fleeting and most of them disappeared, but now everything becomes indexed and searchable. So I ask myself is forgetting thoughts a feature of thinking?
Key Insight
When I structure my thinking it uncovers patterns that hide in my ramblings. By automating this structuring via the summarizing with AI, am I working toward selection? If that is the case I still forget things as they are not selected. So what happens when selection is done automatically and externalized? Does it allow for contradictions?